결론적으로 cra-template 모듈을 관리하는 facebook 측에서 dependencies를 업데이트 해줘야 해결이 되는 문제인데.. facebook 에서는 정책을 변경해서, react 프로젝트 생성 시, framework와 함께 프로젝트를 생성하는 방법을 권장하고 있습니다.
내용을 간략히 요약하자면, 웹 사이트 혹은 웹 앱을 개발할 때, react 를 이용하는 framework을 사용하는 것을 권장하니, 이제부터는 create-react-app은 대신, create-next-app 이나 create-remix 등의 명령어를 이용해서 프로젝트를 생성하라고 하네요..
여튼 아직 create-react-app을 필요로 하시는 분들을 위해 작성한 포스팅이니, 잘 활용하시면 좋겠습니다.
요약
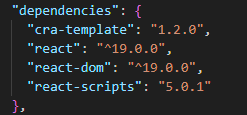
1. react 19는 create-react-app 으로 프로젝트 생성시 에러가 발생함
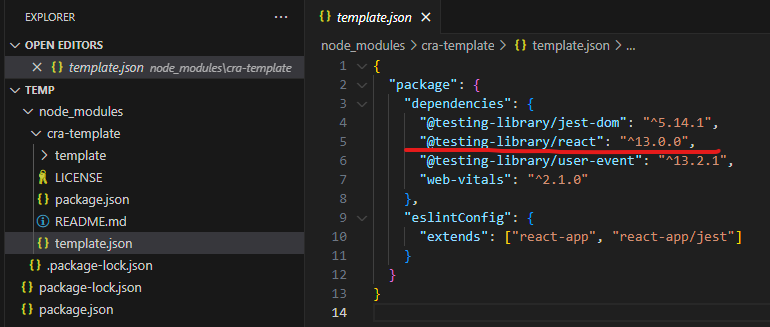
2. 이유는 create-react-app 에서 참조하는 모듈 cra-template 에서, react 18을 참조하는 오래된 라이브러리를 참조하고 있기 때문임
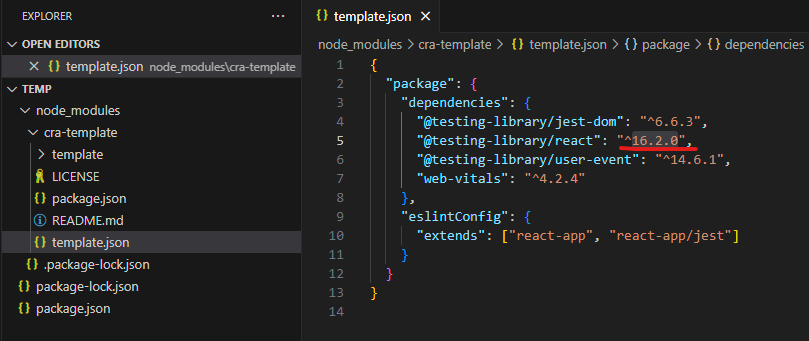
3. 이를 우회하기 위해서, cra-template 을 다운로드 해서, 참조 모듈의 버전을 올려주고,
4. create-react-app 명령어 실행시 편집한 버전의 cra-template 경로를 template 옵션으로 지정해 주면 됨
Singleton 패턴은 전체 프로그램 스콥에서, 특정 클래스를 사용할 때, 단 하나의 인스턴스만 생성해서 사용하는 패턴입니다. 하나의 인스턴스를 사용하게 되면 다음과 같은 장점이 있습니다.
- 공유 자원에 대해서 동시 접근을 제한할 수 있습니다.
- 전역에서 사용가능한 리소스를 생성할 수 있습니다.
- 프로그램 스콥에서 단 하나의 인스턴스만 생성해서 사용하기 때문에 메모리 낭비를 막을 수 있습니다.
모듈 레벨의 Singleton
python에서는 기본적으로 모든 module 은 singleton 으로 정의되어 있습니다. 다음의 예시는 하나의 프로그램 내에서 실행하거나 혹은 동일 shell에서 실행해야 확인이 가능합니다.
## singleton.py
# shared_variable에 초기값 지정
shared_variable = "init value"
## module1.py
import singleton
# 원래 shared_variable에 있는 내용을 확인
print(singleton.shared_variable)
# shared_variable에 내용을 추가
singleton.shared_variable += ", some text"
## module2.py
import singleton
# shared_variable에 있는 내용을 확인
print(singleton.shared_variable)
실행결과
클래스 레벨의 Singleton
이번에는 클래스를 정의해서 singleton 패턴을 구현해 보도록 하겠습니다.
python에서는 클래스의 생성자에서 특정 attribute을 정의해서 항상 같은 값을 바라보는 결과를 리턴하게 처리하면 됩니다.
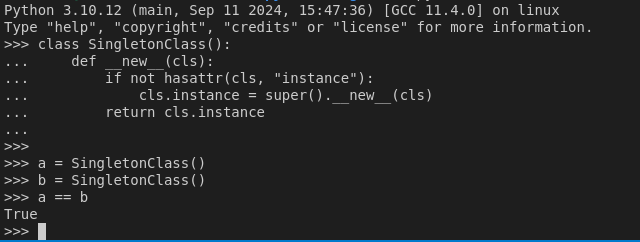
class SingletonClass():
def __new__(cls):
if not hasattr(cls, "instance"):
cls.instance = super().__new__(cls)
return cls.instance
python shell에서 다음과 같이 실행해 보면, SingletonClass로 생성한 instance의 결과가 같다는 것을 알 수 있습니다.
PostgreSQL에서는 Role을 정의해서 DB 이용에 대한 권한을 부여합니다. 다른 DB의 user와 비슷한 개념이지만 좀 더 포괄적으로 사용할 수 있습니다.
여기서는 testuser 라는 role을 생성할 예정이고, 해당 role에게 testdb에 접속해서 public schema 에 있는 테이블을 사용하는 권한을 부여하는 방법에 대해서 알아보도록 하겠습니다.
ROLE 생성하기
Role 생성은 CREATE ROLE statement를 사용합니다.
CREATE ROLE testuser;
cf. role 이름은 '소문자'만 허용이 되는 것 같습니다. 생성시에 이름을 대문자로 입력해도 '소문자'로 생성이 되네요..
ROLE 확인하기
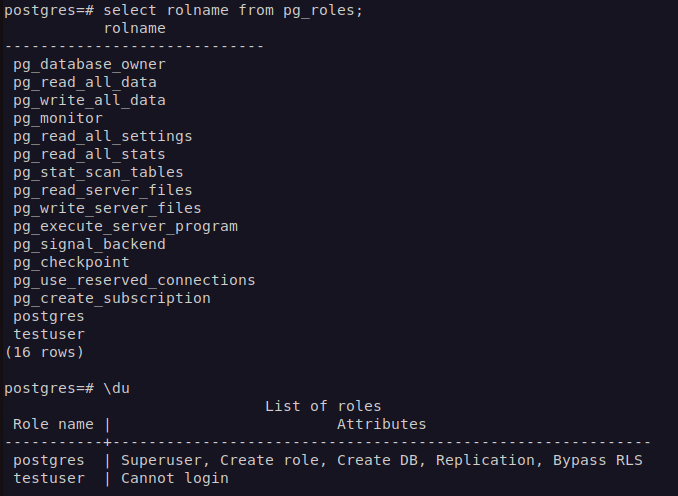
생성된 Role은 다음의 statement로 확인이 가능합니다.
SELECT rolname FROM pg_roles;
혹은 psql 에서는 아래 command를 이용할 수도 있습니다.
\du
ROLE 에 속성 추가/변경 하기
위에서 생성된 role은 아무런 권한이 부여되지 않았기 때문에, 아무것도 할 수 없습니다. 로그인 조차 할 수 없기 때문에, 필요한 속성을 추가해 줘야 합니다. ALTER ROLE statement 를 이용하여 지정한 password를 이용해서 로그인을 할 수 있는 권한을 부여합니다.
ALTER ROLE testuser [WITH] LOGIN PASSWORD 'password';
WITH는 LOGIN, PASSWORD 같은 옵션 앞에 붙인다고 되어 있는데, 생략해도 되는 것 같습니다. ( PostgreSQL 16 기준)
위의 구문으로 DB 테이블에 대한 권한을 부여하면, 권한을 줄 때 당시에 있던 테이블에 대해서만 권한이 적용되며, 나중에 추가한 테이블에 대한 권한은 자동으로 추가되지 않습니다. 모든 새로 생성된 테이블에 대한 권한을 자동으로 추가해 주려면 아래와 같은 구문을 실행해 줍니다.
ALTER DEFAULT PRIVILEGES IN SCHEMA public GRANT SELECT ON TABLES TO testuser;
DB 사용 권한 제거하기
위에서 생성한 DB 권한은 Revoke statement로 제거할 수 있습니다.
REVOKE ALL PRIVILEGES ON ALL TABLES IN SCHEMA public FROM testuser;
cf. 테이블 별 사용 권한 확인
\dp <tablename>
ROLE 제거하기
위에서 생성했던 Role은 DROP ROLE statement로 제거할 수 있습니다. 하지만 그 전에 부여했던 모든 권한을 DB별로 모두 제거해 줘야 합니다.
권한 제거는 DROP OWNED statement를 이용합니다. 아래와 같이 사용하면 됩니다.
concurrent.futures.Excutor 는 비동기 요청을 수행할 때 필요한 메써드들을 정의해 둔 추상 클래스 입니다. 여기에는 submit, map, shutdown 메써드들이 정의되어 있습니다.
submit
수행될 요청을 제출하는 메써드입니다. 결과로 (뒤에서 설명할) Future 인스턴스를 반환합니다.
map
같은 function에 list형태로 정의된 매개변수들을 각각 전달해서 수행하는 경우 사용합니다.
shutdown
executor에게 할당된 리소스를 정리하라는 signal을 보냅니다. shutdown이 호출된 executor에게 submit 혹은 map 를 호출하면, RuntimeError가 발생합니다.
참고: shutdown 을 호출했다고 해서, 수행 중인 모든 동작이 바로 멈추는 것은 아닙니다. 다만 cancel_futures 매개변수 값에 따라서, 아직 시작되지 않고 대기중인 요청을 바로 취소할 건지, 아니면 대기중인 요청까지 모두 끝나고 나서 리소스를 정리할지가 결정됩니다.
python (버전 3.12.4 기준)에서 기본으로 제공되는 executor에는 ThreadPoolExecutor와 ProcessPoolExecutor 가 있습니다. 이름에서 유추할 수 있듯이, ThreadPoolExecutor는 요청을 수행할 때, ThreadPool을 사용하고, ProcessPoolExecutor는 요청을 수행할 때, ProcessPool을 사용합니다.
Process 와 Thread의 차이를 간략하게 정리하면, Process는 독립적으로 수행되며, 메모리 등의 리소스를 따로 할당해서 수행하게 됩니다. Thread는 Process 내에서 수행이 되며, 하나의 Process 안에서 수행되는 Thread들 간에는 리소스를 공유하게 됩니다.
따라서 ProcessPoolExecutor의 경우, 요청들이 Process 단위로 수행되기 때문에, 수행시에 Process에게 리소스를 따로 할당되어야 하기 때문에, overhead가 발생됩니다. 반면 ThreadPoolExecutor의 경우, 리소스가 공유되기 때문에 리소스 할당에 따른 overhead는 없지만, 잘못 사용하게 되면 deadlock이 발생할 수 있습니다.
결론을 이야기하면, 요청 하나 하나의 수행 작업이 오래걸리는 경우 (CPU-bound tasks)에는 리소스 할당에 시간이 소요되더라도 ProcessPoolExecutor가 적합하고, 처리할 데이터가 많지만, 하나 하나의 수행 작업은 빠르게 처리되는 경우 (I/O bound tasks)에는 ThreadPoolExecutor를 사용하는 것이 좋습니다.
Future
executor에게 요청을 submit하면, Future 인스턴스를 반환해 줍니다. 이 Future 인스턴스를 통해서, executor에게 전달한 요청의 상태를 확인할 수 있습니다. 다음은 Future 객체에서 사용할 수 있는 method 들 입니다. (일부만 발췌했으며 전체 리스트를 확인하고 싶으시면 다음의 링크를 참하세요. https://docs.python.org/3/library/concurrent.futures.html)
canceled
수행될 요청이 취소되었는지에 대한 결과를 돌려줍니다.
running
요청이 지금 현재 수행되고 있는지 상태를 돌려줍니다.
done
요청이 취소되었거나 완료되었으면 True를 돌려줍니다.
cancel
아직 대기 중인 요청에 한해서 요청을 취소합니다.
result
요청 수행에 대한 결과를 돌려줍니다. 만약 요청이 아직 끝나지 않았다면, 결과가 나올때까지 기다립니다. (block)
Module functions
concurrent.futures에 정의되어 있는 futures 에서 사용하는 funciton들 입니다. future 요청은 한 가지 요청만 비동기로 처리하는 경우도 있지만, 보통의 경우 여러 요청을 동시에 처리하기 위해서 많이 사용되기 때문에, 전체 요청들에 대한 결과를 받아서 처리해야 하는 경우, 아래의 function들을 사용하게 됩니다.
wait
Future 인스턴스들의 요청이 끝날 때까지 기다립니다. timeout을 지정할 수도 있고, return_when argument를 이용해서 첫 번째 요청이 끝날때, 처음 exception 이 발생했을 때, 모든 요청이 다 처리되었을 때 등의 옵션을 지정할 수 있습니다.
as_completed
Future 인스턴스들의 iterator를 반환해 줍니다. iterator는 generator처럼 동작합니다. 완료된 요청 순으로 결과가 나온 Futuer 인스턴스를 yield 해 줍니다. (비동기적으로 결과를 반환해 줍니다.)
Futures 사용 예제
아래 코드는 간단히 작성한 사용 예제 입니다. (docs.python.org 에 있는 예시를 활용하였습니다.)
먼저 map을 이용해서 요청을 처리하는 예시입니다.
import concurrent.futures
import urllib.request
TEST_URLS = ['https://www.google.com', 'https://www.naver.com', 'https://www.tistory.com']
def load_url(url):
try:
with urllib.request.urlopen(url) as conn:
return url, conn.read(), None
except Exception as exc:
return url, None, str(exc)
with concurrent.futures.ThreadPoolExecutor() as executor:
for url, data, err in executor.map(load_url, TEST_URLS, timeout=60):
if data:
print('%r page is %d bytes' % (url, len(data)))
else:
print('%r generated an exception: %s' % (url, err))
map은 as_completed 와 비슷한데, 결과 iterator에는 Future 인스턴스가 아닌, 인스턴스의 result 들을 반환해 줍니다. map을 억지로 풀어쓴다면 다음과 같습니다.
with concurrent.futures.ThreadPoolExecutor() as executor:
for url, data, err in [f_instance.result() for f_instance in
concurrent.futures.as_completed([executor.submit(load_url, url) for url in TEST_URLS])]:
if data:
print('%r page is %d bytes' % (url, len(data)))
else:
print('%r generated an exception: %s' % (url, err))
여기서 이야기하고자 하는 바는, map의 경우에는 Future 인스턴스에서 result를 읽는 과정이 포함되어 있기 때문에, 특정요청에서 exception 이 발생하는 경우, iterator를 수행하는 과정에서 exception이 발생하게 됩니다. 이 exception으로 문제가 생기는 것을 막기 위해서는, 요청 내에서 exception이 발생하더라도 같은 포맷으로 결과를 리턴해 줄 수 있게 디자인해야 합니다.
위의 예시를 as_completed 를 사용해서 변경하면 다음과 같습니다.
import concurrent.futures
import urllib.request
TEST_URLS = ['https://www.google.com', 'https://www.naver.com', 'https://www.tistory.com']
def load_url(url, timeout):
with urllib.request.urlopen(url, timeout=timeout) as conn:
return conn.read()
with concurrent.futures.ThreadPoolExecutor() as executor:
future_to_url = {executor.submit(load_url, url, 60): url for url in TEST_URLS}
for future in concurrent.futures.as_completed(future_to_url):
url = future_to_url[future]
try:
data = future.result()
except Exception as exc:
print('%r generated an exception: %s' % (url, exc))
else:
print('%r page is %d bytes' % (url, len(data)))
여기서는 as_completed가 future instance 에서 결과를 받아오는 시점에서 exception을 처리할 수 있기 때문에 요청에서 Exception 이 발생한다고 해도, iterator에서 처리가 가능합니다.
마지막으로 wait을 사용하면, list에 future instance를 호출한 순서대로 저장하여, list를 이용해서 호출한 순서대로 결과를 처리할 수 있습니다. 참고로 wait function은 반환값으로 as_completed와 같이 처리된 순서대로 결과를 처리할 수 있는 generator 형태의 iterator를 돌려줍니다.
import concurrent.futures
import urllib.request
TEST_URLS = ['https://www.google.com', 'https://www.naver.com', 'https://www.tistory.com']
def load_url(url, timeout):
with urllib.request.urlopen(url, timeout=timeout) as conn:
return conn.read()
with concurrent.futures.ThreadPoolExecutor() as executor:
future_list = [executor.submit(load_url, url, 60) for url in TEST_URLS]
concurrent.futures.wait(future_list)
for idx, future in enumerate(future_list):
url = TEST_URLS[idx]
try:
data = future.result()
except Exception as exc:
print('%r generated an exception: %s' % (url, exc))
else:
print('%r page is %d bytes' % (url, len(data)))
Python 의 decorator 는 funciton 이나 class에 코드의 내용을 변경하지 않고도 기능을 확장할 수 있는 아주 유용한 툴입니다.
Decorator를 이해하기 위해서는 몇 가지 알아두면 좋은 내용들이 있어서 먼저 알아보고, decorator에 대해서 알아보도록 하겠습니다.
First Class Objects
먼저 한국말로는 일급 객체라고 이야기하는 first class objects에 대해서 알아보겠습니다. 일급 객체는 다른 객체들에 일반적으로 적용 가능한 연산을 모두 지원하는 객체를 가리킵니다. 보통 함수에 인자로 넘기기, 수정하기, 변수에 대입하기와 같은 연산을 지원할 때 일급 객체라고 합니다.
일급 객체는 다음과 같은 특징이 있습니다. (by 로빈 포플스톤)
모든 요소는 함수의 실제 매개변수가 될 수 있다.
모든 요소는 함수의 반환 값이 될 수 있다.
모든 요소는 할당 명령문의 대상이 될 수 있다.
모든 요소는 동일 비교의 대상이 될 수 있다.
Python에서는 function 도 일급 객체로 분류됩니다. 아래 예시를 보면 쉽게 이해가 될 겁니다.
def add_10(val):
return val + 10
def run_func(f, val):
return f(val)
# (add_10 함수를) 매개변수로 사용
run_func(add_10, 10)
# (add_10 함수를) 반환값으로 사용
def plus_10():
return add_10
# (add_10 함수를) 다른 변수에 할당
plus_ten = add_10
# 비교의 대상으로 사용
print(add_10 is run_func)
여기서 일급객체를 특별히 설명한 이유는 Python에서는 "function"이 일급객체이기 때문에, 매개변수로 사용할 수 있으며, function을 리턴 값으로 사용할 수 있다는 특징을 상기시키기 위함입니다. 많은 프로그래밍 언어들이 function을 일급객체로 사용하기 때문에 특별히 거부감이 있는 컨셉은 아닐겁니다.
Inner Functions
Python에서는 함수의 내부에 다른 함수를 정의하는 것이 가능합니다. 내부에 정의된 함수를 inner functions 라고 부르는 데요.. 한국말로는 내부 함수가 적절할 표현일 것 같습니다. (어떤 분은 내장 함수라고 번역하시기도 했는데요, 일반적으로 내장함수는 프로그래밍 언어에서 지원해주는 기본 함수를 이야기 하기 때문에 내부 함수라는 표현이 더 적절할 것 같습니다.)
아래 예시를 보면, parent 함수 내에 child 함수를 정의해서 사용하였습니다. child 함수의 scope은 parent 함수 내에서만 유효합니다.
위의 예시에는 decorator() 함수와, some_function() 함수가 정의되어 있고, decorator() 함수에는 wrapper() 라는 내부 함수가 정의되어 있습니다. 그리고 마지막 줄에서는 some_function()을 decorator() 함수를 실행한 결과로 변경하였습니다.
여기서 some_function()을 실행하면 아래와 같은 결과가 화면에 출력될 겁니다.
>>> some_function()
BEFORE
RUN
AFTER
원래 some_function() 함수에서는 "RUN"만 출력해 주는데, decorator()를 통해서 변경한 some_function()은 "BEFORE", "RUN", "AFTER"를 차례로 출력해 줍니다. 쉽게 이야기해서 decorator() 함수가 some_function() 함수를 감싸서, 변경해 주었다고 할 수 있습니다.
실제로 decorator를 사용할 때는, 아래와 같이 @ 기호를 붙여서 함수 앞에 붙여 주면 됩니다. 아래 예시에서는 @decorator 는 some_function = decorator(some_function) 를 짧게 표현해 주는 방법으로 생각할 수 있습니다.
위의 명령어를 실행하면, all.tar 파일이 생성되며, 원래 txt 파일들은 삭제되지 않는다.
@ tar 명령어를 이용해서 묶인 파일을 해제하기
> tar -xvf all.tar
위의 명령어를 실행하면 all.tar 파일에 묶여 있던 txt 파일들이 생성되며, all.tar 파일은 삭제되지 않는다.
묶을 때는 c 옵션, 해제할 때는 x 옵션
-v 옵션은 verbose를 의미하며, 압축 / 해제되는 파일을 화면에 표시되게 해준다.
-f 옵션은 파일명을 지정할 때 사용한다.
@ 하나의 파일로 묶으면서 gzip으로 압축하기
-z 옵션을 추가한다.
> tar -czvf all.tar.gz *.txt
@ 하나의 파일로 묶으면서 bzip2로 압축하기
-j 옵션을 추가한다.
> tar -cjvf all.tar.bz2 .
@ 압축된 tar 파일 해제하기
> tar -xvf all.tar.gz
> tar -xvf all.tar.bz2
cf. all.tar.gz 파일을 gzip (혹은 gunzip)으로 압축 해제하면, all.tar 파일이 생성된다. gzip (혹은 gunzip)으로 압축 해제해서 생성된 all.tar 파일은 -cvf 옵션으로 그냥 tar로 묶은 파일과 동일하다.
cf2. 압축 혹은 묶을 대상 파일들을 '*' 대신 '.' 으로 쓰는 이유는.. '*' 을 사용할 경우, 현재 폴더에 있는 hidden 파일들이 포함되지 않기 때문임 (sub 폴더 안에 있는 hidden 파일들은 포함이 됨)
응용편
@ tar에서 pigz을 이용하기
> tar -cvf all.tar.gz -I pigz .
현재 경로에 있는 모든 파일들을 pigz를 사용해서 압축하라는 의미
-I 옵션은 --use-compress-program 의 짧은 표현
아래 명령어와 결과는 같지만 CPU 코어 수에 따라 훨씬 빠른 결과가 나올 수 있음
> tar -czvf all.tar.gz .
아래와 같이 사용도 가능함
> tar -cvf - . | pigz > all.tar.gz
압축을 해제할 때도 마찬가지로 사용가능
> tar -xvf all.tar.gz -I pigz
@ tar 작업시 working directory 지정하기
> tar -xzvf all.tar.gz -C ../test
-C 옵션은 --directory 의 짧은 표현으로, 원래 GNU 스펙상으로는 tar로 묶는 경우에도 작동하게 되어 있는데.. 실제로 많은 linux 배포판에서 묶는 경우에는 제대로 작동하지 않고, 해제시에만 제대로 작동한다고 함.. Ubuntu 에서 테스트시에도 묶는 경우에는 제대로 동작하지 않았음.
만약 묶는 경우에도 directory 옵션을 사용하고 싶다면.. 아래와 같이 압축될 파일명에 절대 경로를 지정하면, 우회해서 사용이 가능함.
> cd /opt/test && tar -cvf /root/test.tar.gz -I pigz . && cd -
@ standard output
gzip, gunzip, pigz 등은 -c 옵션으로 결과를 standard out (화면출력) 으로 처리가 가능.